

本文重點
- AI 在特定任務上的高準確率,不等於能取代整個職業
- 醫生的工作由多個性質不同的環節組成,適合自動化的只是其中一部分
- 「取代」框架讓討論停在錯誤的層面,真正的問題是哪些工作應該由人做、哪些不應該
- WHO 建議以流程重設計為前提,而非單純疊加數位工具
- AI 有沒有可能真的取代醫生?
- 從技術角度,AI 在特定任務上超越醫師的現象已經存在,並且會持續擴展。但「取代醫生」需要 AI 同時具備臨床判斷、倫理推理、情境溝通與法律責任承擔能力,這些能力的整合目前尚未出現可靠的系統。更根本的問題是:當一個決策出錯,誰來負責?技術能力的邊界,往往不是由準確率定義,而是由責任歸屬定義。
- 小型診所有資源導入 AI 工具嗎?
- 資源限制是現實問題。但 AI 工具的導入不一定需要大規模系統建設。目前已有一些針對基層診所設計的低成本解決方案,例如自動化病歷摘要、症狀初篩問卷、藥物查詢輔助。評估導入時,建議從「解決最耗時的一個具體問題」開始,而不是追求全面數位化。
- 電子病歷系統已經很麻煩了,AI 是解方還是讓問題更複雜?
- 這取決於 AI 工具的設計是否以減少操作步驟為目標。如果只是在既有 EHR 系統上疊加 AI 功能,而不重新設計工作流程,問題很可能更複雜。真正有效的做法,是重新評估哪些資訊需要醫師輸入、哪些可以自動填入,從流程設計開始,而不是從功能追加開始。

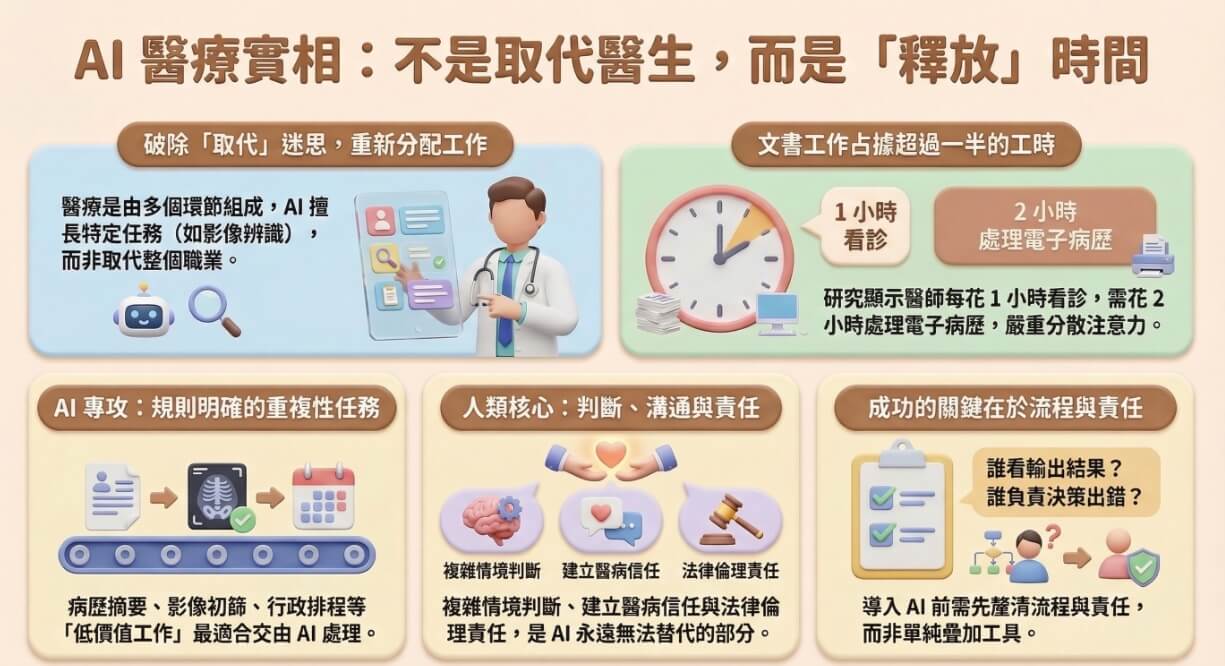
一、「取代」是錯的問題框架
這個問題本身設定了一個錯誤的框架。 醫療不是單一任務,而是由數十個性質截然不同的工作環節組成,有的適合自動化,有的不行。把整個職業用「取代」或「不取代」來討論,等於沒有分析。
「取代醫生」的討論之所以一再出現,原因通常是某項 AI 工具在特定任務上的表現超越了平均醫師——例如辨識皮膚病變、讀取 X 光片、偵測心電圖異常。這類消息被放大解讀成「AI 可以取代醫生」,但這忽略了一個關鍵事實:那只是醫生工作中的一小部分,而且往往不是最占時間、最消耗注意力的那部分。
真正值得問的是:醫生每天的工時,有多少是花在這種可以自動化的任務上?剩下的呢?
世界衛生組織(WHO)在報告《Global strategy on digital health 2020-2025》中指出,全球醫療衛生人力短缺的核心問題之一,正是行政與文書工作過度佔用了臨床時間。WHO 報告建議各國政府評估數位工具在減輕非臨床負擔方面的潛力,但強調「工具的導入必須以流程重設計為前提,而非單純的疊加」。
這個觀察點出了問題的本質:討論的重點不該是取代,而是重新分配工作。
摘要
- AI 在特定任務上的高準確率,不等於能取代整個職業
- 醫生的工作由多個性質不同的環節組成,適合自動化的只是其中一部分
- 「取代」框架讓討論停在錯誤的層面,真正的問題是哪些工作應該由人做、哪些不應該
- WHO 建議以流程重設計為前提,而非單純疊加數位工具
二、醫生的時間都花在哪裡?
不是。 多項研究顯示,醫師在臨床實際接觸病人的時間,在總工時中佔比往往不到一半,其餘時間大量用於病歷記錄、行政作業、協調排班、回覆院內訊息,以及應對資訊系統的操作摩擦。
2016 年發表於《內科醫學年鑑》(Annals of Internal Medicine)的研究顯示,美國門診醫師每花 1 小時在病人身上,就需要額外花 2 小時在電子病歷(EHR)記錄上。這個比例在台灣雖因體制不同而有所差異,但結構性問題是一致的:資訊系統設計以資料儲存為優先,而非以醫師使用效率為優先。
這不只是時間分配的問題,而是注意力的問題。在高強度工作環境中,注意力是有限的資源。每一次切換到文書作業,就是一次對臨床判斷注意力的消耗。當醫師在問診時一邊盯著螢幕輸入,這種狀態本身就影響了溝通品質。
「醫師花大量時間在文件記錄上,這不只是效率問題,而是病患安全問題。當醫師疲憊且分心時,臨床錯誤的機率就會上升。」— 《新英格蘭醫學雜誌》(NEJM)2022 年編輯觀點
低價值工作的類型,大致可以分成幾類:
一、重複性資訊輸入:同一筆資料在多個系統重複填寫。病患的過敏史、用藥記錄、慢性病史,在掛號系統、護理系統、醫師作業站三個地方各填一次,是很常見的現象。
二、被動式資訊整理:在問診前,醫師需要自行從系統中蒐集病歷摘要、上次回診記錄、近期檢驗數值。這個動作本身不需要醫師的臨床判斷,但卻往往由醫師親自執行。
三、行政性通知與協調:藥局確認、轉介單填寫、保險文件申請、會診安排。這些工作的核心是資訊轉移,而非臨床決策。
四、低複雜度的問答:「這個藥吃完之後要複診嗎?」「這個症狀要掛哪一科?」「下次回診帶什麼資料?」這類問題在門診後大量湧入,卻不需要醫師來回答。
這些工作的共同特徵是:有固定答案、規則明確、不需要情境判斷。這正是 AI 工具最擅長處理的區域。

重點摘要
- 醫師每天臨床接觸病人的時間,往往不到總工時的一半
- 低價值工作主要包括:重複資訊輸入、被動資訊整理、行政性通知、低複雜度問答
- 低價值工作的共同特徵:規則明確、有固定答案、不需情境判斷
- 注意力分散是文書過載帶來的次生問題,直接影響臨床溝通品質
三、哪些工作適合 AI 介入,哪些不行?
適合 AI 介入的,是規則明確且資料充足的任務;不適合的,是需要情境判斷、倫理責任或人際互動的環節。 這條界線不是技術能力的上限,而是責任分配的設計問題。

這張表格的關鍵不在「AI 能不能做到」,而在**「這個判斷的責任誰來承擔」**。當一個決策出錯,需要有人能被追究、能解釋、能修正——這部分是技術本身無法替代的。以影像判讀為例,這是目前 AI 在醫療領域表現最穩定的項目之一。皮膚病變辨識、乳房攝影異常偵測、眼底病變篩查——這些任務有 AI 工具達到甚至超越專科醫師平均準確率。但臨床導入的設計不是「AI 取代醫師判讀」,而是「AI 先篩一輪,醫師做最終確認」。這個設計的邏輯是:
- AI 把需要醫師注意的案例篩出來,減少醫師瀏覽正常案例的工時
- 醫師的注意力集中在高風險或模糊邊界的案例
- 最終判斷仍由醫師負責,責任歸屬清楚
這是「減少低價值工作、保留高價值判斷」的設計,而不是取代。
| 工作類型 | AI 介入評估 | 說明 |
|---|---|---|
| 病歷摘要生成 | 適合 | 有結構化資料即可產生,減少醫師整理時間 |
| 影像初步篩查(X 光、病理切片) | 適合(輔助) | 高重複性模式識別;複雜案例仍由醫師最終確認 |
| 藥物交互作用警示 | 適合 | 規則庫比對,有明確觸發條件 |
| 慢性病患異常數值通報 | 適合 | 閾值設定後自動觸發,不需臨床判斷 |
| 預約排程與提醒 | 適合 | 流程自動化,不涉及醫療決策 |
| 症狀初步分流 | 適合(輔助) | 輕症問診導引可用 AI;不確定或複雜症狀仍需人工確認 |
| 臨床診斷判斷 | 僅輔助 | 最終診斷仍由醫師負責,責任不可轉移 |
| 病患溝通與心理支持 | 不適合替代 | 工具可輔助資訊提供,但核心在人的在場與回應 |
| 高風險治療決策 | 不適合替代 | 醫師需承擔法律與倫理責任 |
| 倫理性決策(如維生判斷) | 不適合 | 需要人與家屬共同承擔,工具無法代理 |
「AI 在醫療影像領域的最佳應用,不是替代放射科醫師,而是讓放射科醫師的注意力能集中在真正需要專業判斷的案例上。」— Eric Topol,《Deep Medicine: How Artificial Intelligence Can Make Healthcare Human Again》,Basic Books,2019
四、導入 AI 不等於解決問題——整合才是關鍵
因為大多數導入只解決了技術部分,忽略了流程設計、角色責任與使用者接受度。 一個準確率很高的 AI 工具,如果在錯誤的時間點插入工作流程,或者輸出結果沒有明確的後續行動設計,它帶來的可能是更多的摩擦,而不是效率。
這個問題的根因,在於把「導入 AI」當成目的,而不是把「解決特定問題」當成目的。
醫療 AI 導入失敗的常見原因,可以分成五個層面:
| 失敗類型 | 常見表現 | 根因 |
|---|---|---|
| 資料問題 | 模型表現與測試時落差大 | 現場資料品質、分布與訓練資料不同 |
| 流程問題 | 工具有人用,但效果不明顯 | 工具插入點不對,沒有減少關鍵瓶頸 |
| 角色問題 | 警示很多,沒人處理 | 沒有定義誰負責看、看完後做什麼 |
| 接受度問題 | 工具被繞過或棄用 | 使用者學習成本高,帶來的幫助不直接 |
| 治理問題 | 初期有效,後來效果下降 | 沒有定期審查模型效能的機制 |
這個框架說明的是:問題不是技術不夠好,而是導入方式沒有從問題出發。每一個失敗類型背後都有可以追查的根因,而這些根因在導入前通常是可以預判的。
可執行步驟
在評估一項醫療 AI 工具是否值得導入之前,可以用以下五個問題做基本檢驗:
1. 這個工具要解決的問題,真的是問題的源頭嗎?
舉例:如果病患安全事件的根本原因是交班資訊不完整,問題在資訊傳遞流程,不在缺少一個 AI 提醒系統。先修流程,才看工具。
2. 工具輸出的結果,誰會看?在什麼時間點看?看完之後需要做什麼?
很多 AI 工具有輸出,但沒有人在看。或者有人看,但不知道看到異常警示後該怎麼處理。輸出沒有明確的後續行動設計,就不是有效的工具。
3. 輸入這個工具的資料,現在的品質足夠嗎?
AI 輸出的品質取決於輸入資料。如果電子病歷的結構化程度很低,或者欄位填寫不一致,模型給出的建議可信度就很低。工具導入之前要先評估資料品質。
4. 如果這個工具的建議是錯的,誰負責?怎麼補救?
責任歸屬必須在設計階段就確定,不能等到出事之後再討論。「AI 建議了,醫師照做了,結果不對」——這個場景的責任鏈必須先定義清楚。
5. 使用者有沒有動機用它?它對日常工作是幫忙還是增加負擔?
臨床工作者對新系統的接受度,往往比技術本身更能決定導入成敗。如果使用者需要額外輸入資料才能讓工具運作,而工具的回饋又不夠直接有用,接受度就會很低。
這五個問題沒有標準答案,但如果在導入前無法對每個問題都給出明確回答,導入成功的機率就很低。
重點摘要
- 導入 AI 最常見的失敗原因是把工具插入了錯誤的流程位置
- 評估導入前需要確認:問題定義、輸出設計、資料品質、責任歸屬、使用者接受度
- 責任歸屬不能等到出事後才討論,必須在設計階段就確定
- 模型效能會隨時間變化,需要定期審查機制,否則工具會在不知情的狀況下失效
五、真正的目標:把人的時間還給需要人的部分
讓醫生能把更多時間用在真正需要人做的事:判斷、溝通、承擔責任。 這不是技術願景,而是系統設計的目標。
「需要人的部分」不只是診斷,還包括三個層次:
一、需要情境判斷的複雜案例
同樣的症狀,在不同病患身上意義不同。病患的生活背景、心理狀態、家庭支持系統,都是診斷與治療計畫的重要資訊,而且這些資訊往往不在病歷上。這個層次的判斷,需要人在現場。
二、需要信任建立的溝通
壞消息的告知、治療選項的討論、對病患疑慮的回應——這些對話的品質,不只取決於資訊是否正確,還取決於病患是否感覺被理解、被尊重。這個部分,工具可以輔助(例如提供病情說明的參考資料),但核心是人的在場。
三、需要承擔後果的決策
當一個治療決策風險很高,或者有多個選項且各有代價,最終要有人做出判斷、承擔後果,並能向病患和家屬解釋。這個責任的核心是人的判斷力和可被追責性,不是技術能力。
這三個部分如果因為行政工作、低價值問答、重複輸入而被壓縮,醫療品質就會下降。這才是 AI 在醫療領域最有意義的應用方向——不是取代,而是騰出空間。
以 FHIR(Fast Healthcare Interoperability Resources,醫療資訊互通性資源)為例,這是 HL7 International 制定的醫療資料交換標準,目標是讓不同醫療系統的資料能夠互通。當資料能在系統間流通,醫師就不需要在每次問診前手動蒐集分散在各處的病歷資訊。這是一種技術基礎設施的改善,解決的不是臨床判斷問題,而是資料準備的低價值工作——把這部分時間還給醫師,讓醫師在問診開始時就已經有完整的病患背景,能把注意力放在需要判斷的地方。
這種設計邏輯適用於更廣泛的 AI 工具評估:一個醫療 AI 工具是否有價值,不看功能有多強,而看它把哪些低價值工作移走了,以及移走之後,醫師或病患的哪個需求得到了更好的服務。
這也是一個判斷標準:當評估任何一項醫療數位工具時,可以問「這個工具讓誰的什麼時間被釋放出來?釋放出來之後,那段時間被用在哪裡?」如果這兩個問題都有清楚的答案,這個工具的設計邏輯就是對的;如果答不出來,這個工具很可能只是在既有流程上疊加了一層複雜度。
重點摘要
- AI 在醫療的最終目標是騰出人的時間,用於需要判斷、溝通、承擔責任的場合
- 情境判斷、信任建立、責任承擔,是目前 AI 無法替代的三個核心
- FHIR 等資料互通標準是減少低價值工作的基礎建設,而非直接的臨床解決方案
- 評估 AI 工具的關鍵問題:它把哪些低價值工作移走了?移走之後誰獲益?
AI 有沒有可能真的取代醫生?
從技術角度,AI 在特定任務上超越醫師的現象已經存在,並且會持續擴展。但「取代醫生」需要 AI 同時具備臨床判斷、倫理推理、情境溝通與法律責任承擔能力,這些能力的整合目前尚未出現可靠的系統。更根本的問題是:當一個決策出錯,誰來負責?技術能力的邊界,往往不是由準確率定義,而是由責任歸屬定義。
小型診所有資源導入 AI 工具嗎?
資源限制是現實問題。但 AI 工具的導入不一定需要大規模系統建設。目前已有一些針對基層診所設計的低成本解決方案,例如自動化病歷摘要、症狀初篩問卷、藥物查詢輔助。評估導入時,建議從「解決最耗時的一個具體問題」開始,而不是追求全面數位化。
電子病歷系統已經很麻煩了,AI 是解方還是讓問題更複雜?
這取決於 AI 工具的設計是否以減少操作步驟為目標。如果只是在既有 EHR 系統上疊加 AI 功能,而不重新設計工作流程,問題很可能更複雜。真正有效的做法,是重新評估哪些資訊需要醫師輸入、哪些可以自動填入,從流程設計開始,而不是從功能追加開始。
AI 的輔助建議,醫生需要照著做嗎?
不需要,也不應該照單全收。AI 工具的輸出是「輔助參考」,最終決策仍由醫師負責。問題在於,當 AI 建議非常頻繁且大多時候是對的,醫師可能會降低對建議的懷疑強度,形成所謂的「自動化偏誤」。好的工具設計應該讓醫師容易辨識高信心建議與低信心建議,並在不確定的情況下給出明確提示,而不是讓醫師預設 AI 是對的。
台灣的醫療環境適合導入 AI 工具嗎?
台灣有幾個有利條件:健保資料庫覆蓋率高、電子病歷普及程度較高、有政策層級的數位健康推動框架。挑戰則包括:各醫院資訊系統異質性高、資料標準化程度不足、跨院資料共享有法規限制。整體而言,導入條件比許多國家好,但資料品質與系統整合仍是主要瓶頸,工具選擇需要先確認資料源頭的可用性。



